

spss29.0 mac版是一款专门为mac用户提供的计数据分析新软件,一般又称为ibm spss statistics 29 mac,spss for mac 29,该软件采用类似Excel表格的方式输入与管理数据,且数据接口也较为通用,用户可方便的从其他数据库中读入数据,并且spss还可以分布于通讯、医疗、银行、证券、保险、制造、商业、市场研究以及科研教育等多个领域和行业,同时还具有易用性、灵活性和可扩展性,使用这款软件就能够帮助相关研究、分析人员轻松完成统计分析工作,成为做统计报表的好帮手。
除此之外,spss29.0软件还拥有更智能的数据导入和导出功能,且可更加智能化的读取和写入Excel文件,可根据具有相同格式的值的指定百分比确定列的数据格式,甚至还具有强大的分析技术和能力,可以节省时间,帮助你在数据中快速和容易地找到新的想法,有需要的朋友欢迎前来本站免费下载体验。
ibm spss statistics 29 mac新特性
一、弹性网(Elastic Net)
新的线性弹性网络扩展过程估计一个或多个自变量上因变量的正则化线性回归模型。该图表示该过程的示例输出。
二、套索(Lasso)
新的线性套索扩展估计一个或多个自变量上的因变量的 L1 损失正则化线性回归模型,并包括显示跟踪图和基于交叉验证选择 alpha 超参数值的可选模式。该图表示该过程的示例输出。
三、脊(Ridge)
新的线性 ridge 扩展过程估计一个或多个自变量上的因变量的 L2 或平方损失正则化线性回归模型,并包括用于显示跟踪图和基于交叉验证选择 alpha 超参数值的可选模式。该图表示该过程的示例输出。
四、参数化加速失效时间 (AFT) 模型
新过程使用非循环寿命数据调用参数化生存模型过程。参数化生存模型假设生存时间服从已知分布,并且此分析拟合加速失效时间模型及其相对于生存时间成比例的模型效应。该图表示该过程的示例输出。
五、Pseudo-R2线性混合模型和广义线性混合模型中的度量
Pseudo-R2度量和类内相关系数现在包含在线性混合模型和广义线性混合模型输出中(如果适用)。决定系数 R2是一个经常报告的统计量,因为它表示线性模型解释的方差比例。类内相关系数 (ICC) 是一种相关统计量,用于量化多级/分层数据中由分组(随机)因子解释的方差比例。
六、命令语法
1、GENLINMIXED
输出现在包括Pseudo-R2度量和类内相关系数(适当时)。
2、LINEAR_ELASTIC_NET
新的扩展命令使用 Python sklearn.linear_model.ElasticNet 类,用于估计一个或多个自变量上因变量的正则化线性回归模型。
3、LINEAR_LASSO
新的扩展命令使用 Python sklearn.linear_model.Lasso 类,用于估计一个或多个自变量上因变量的 L1 损失正则化线性回归模型。该命令包括用于显示跟踪图和选择基于交叉验证的 alpha 超参数值的可选模式。
4、LINEAR_RIDGE
新的扩展命令使用 Python sklearn.linear_model.Ridge 类,用于估计一个或多个自变量上因变量的 L2 或平方损失正则化线性回归模型。该命令包括用于显示跟踪图和选择基于交叉验证的 alpha 超参数值的可选模式。
5、MIXED
输出现在包括Pseudo-R2度量和类内相关系数(适当时)。
6、SURVREG AFT
新的扩展命令使用非循环的生命周期数据调用参数化生存模型过程。
7、Python 和R升级
Python 3.10.4 和 R 4.2.0 与 IBM® SPSS® 统计 29 一起安装。
七、删除隐藏未选定案例的功能
选择一部分案例后,未选择的案例将不再隐藏在数据编辑器中,并且不会丢弃未选择的案例。这表示返回到Statistics 27.0.1 及更早版本的行为。
八、小提琴图
图形板模板选择器包括一个新的小提琴图,它是箱形图和内核密度图的混合体。小提琴图显示数据中的峰值,并用于可视化数值数据的分布。与只能显示汇总统计数据的箱形图不同,小提琴图描述了汇总统计数据和每个变量的密度。
九、工作簿模式增强功能
添加了两个新的工作簿工具栏项:“显示/隐藏所有语法窗口”和“清除所有输出”。状态栏上还有一个新按钮,用于在经典(输出和语法)和工作簿模式之间切换。
十、搜索增强功能
“搜索”功能现在提供了用于直接在工具栏字段中输入术语以及在下拉窗格中查看结果的选项。
软件亮点
1、操作简便
界面非常友好,除了数据录入及部分命令程序等少数输入工作需要键盘键入外,大多数操作可通过鼠标拖曳、点击“菜单”、“按钮”和“对话框”来完成
2、编程方便
具有第四代语言的特点,告诉系统要做什么,无需告诉怎样做。只要了解统计分析的原理,无需通晓统计方法的各种算法,即可得到需要的统计分析结果。对于常见的统计方法,SPSS的命令语句、子命令及选择项的选择绝大部分由“对话框”的操作完成。因此,用户无需花大量时间记忆大量的命令、过程、选择项
3、功能强大
具有完整的数据输入、编辑、统计分析、报表、图形制作等功能。自带11种类型136个函数。SPSS提供了从简单的统计描述到复杂的多因素统计分析方法,比如数据的探索性分析、统计描述、列联表分析、二维相关、秩相关、偏相关、方差分析、非参数检验、多元回归、生存分析、协方差分析、判别分析、因子分析、聚类分析、非线性回归、Logistic回归等
4、数据接口
能够读取及输出多种格式的文件。比如由dBASE、FoxBASE、FoxPRO产生的*.dbf文件,文本编辑器软件生成的ASCⅡ数据文件,Excel的*.xls文件等均可转换成可供分析的SPSS数据文件。能够把SPSS的图形转换为7种图形文件。结果可保存为*.txt及html格式的文件
spss29.0 mac版多元logistic回归分析的使用技巧
一、概述
1、数据
- 这是一份对不同人群早餐选择的调查数据,通过SPSS的多元回归分析,可以将人群特征变量对早餐类型进行分析,找到它们之间的关系。
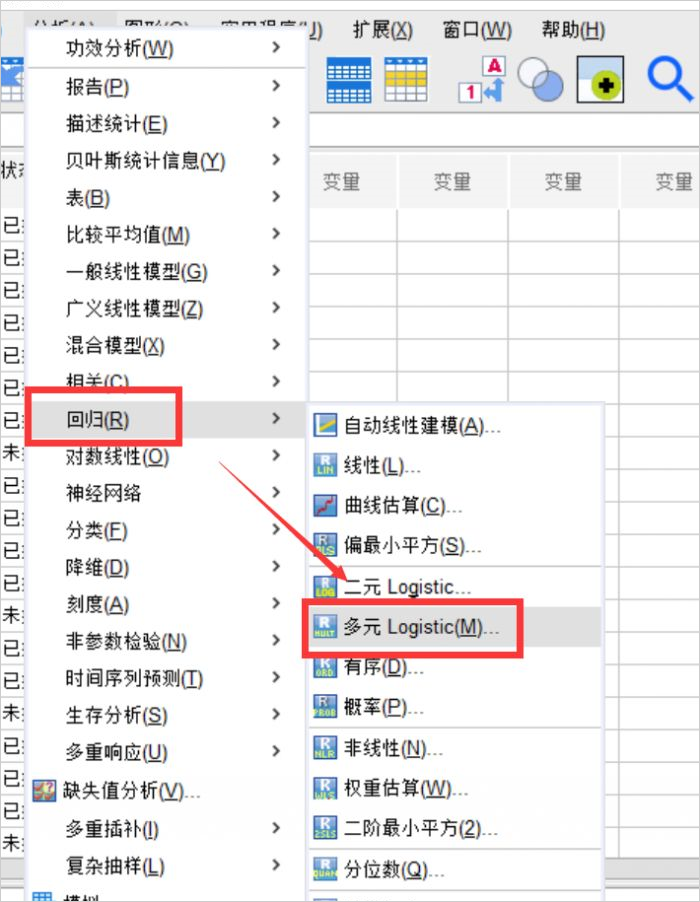
2、功能位置
- 在“分析”菜单下,我们可以找到“回归”中的“多元logistic”分析,进入多元回归分析的窗口。
二、分析方法
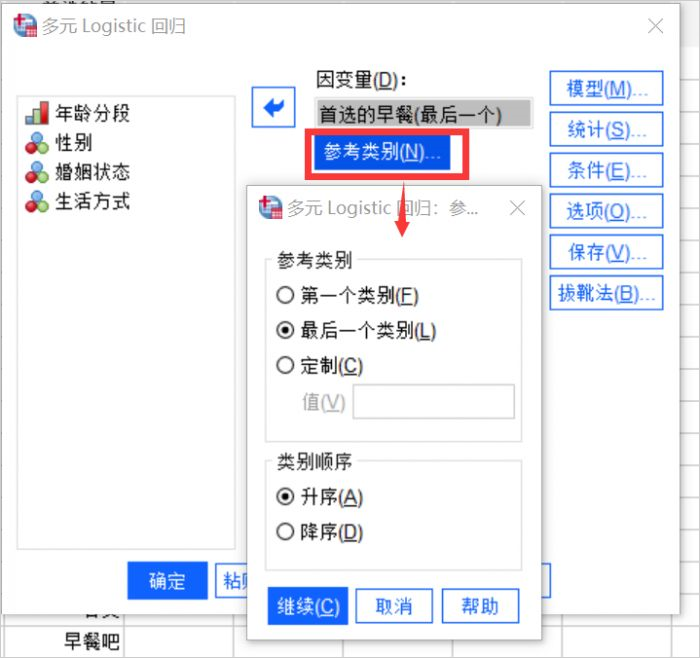
1、因变量设置
- 因变量就是跟随自变量变化的量,本例中指的是“首选的早餐”这一变量。
- 点击“参考类别”,设置因变量的参考类别,这是分析时的参考样,我们设置为所有类别都和最后一个类别对比,类别顺序选择升序。
2、因子和协变量
- 因子可以简单理解为自变量,我们这里将年龄分段、婚姻状况和生活方式作为因变量处理。
- 协变量是分析过程中需要控制的、对因变量有一定影响的控制变量,这里设置为性别。
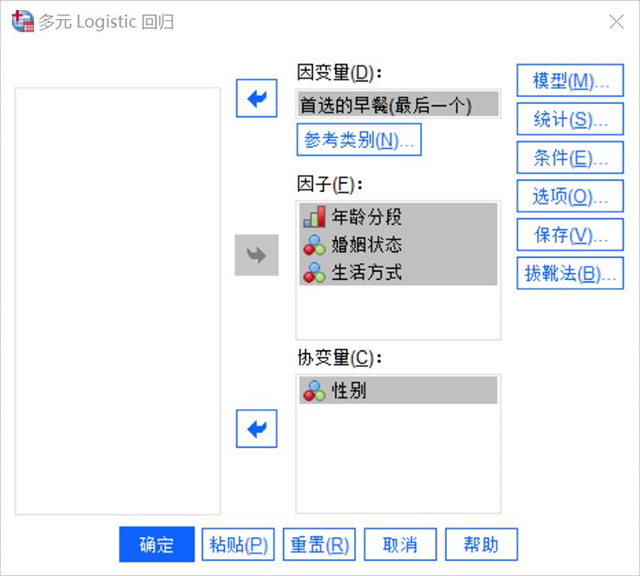
3、分析模型
- SPSS的多元回归分析有三类模型可选,主效应是指设置好的因子和协变量与因变量之间的关系分析;全因子模型既包括主效应,也包括因子和协变量之间的交互分析;定制步进式则可以有用户自己定义分析类型。
- 我们这里选择主效应进行分析即可。
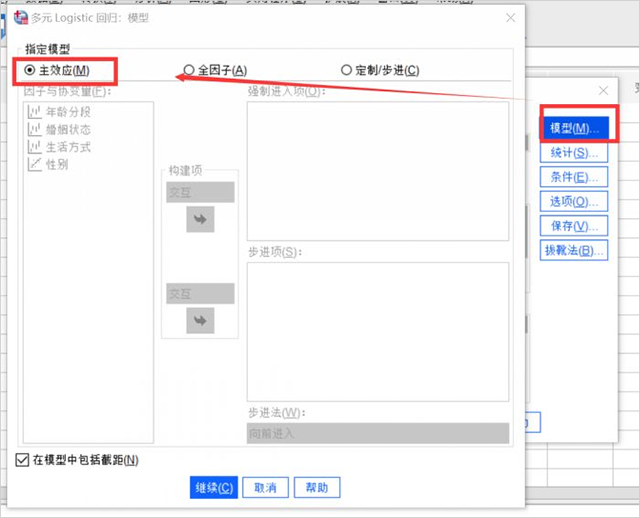
4、统计设置
- 这个窗口内设置的是需要进行的统计数据分析,包括多类统计数据可选,我们勾选模型下的伪R方、单元格可能性、步骤摘要、分类表、模型拟合度信息和拟合度,参数下的估计(置信区间设置为95%)和似然比检验。
- 定义子群体选择“由因子和协变量定义的协变量模式”。
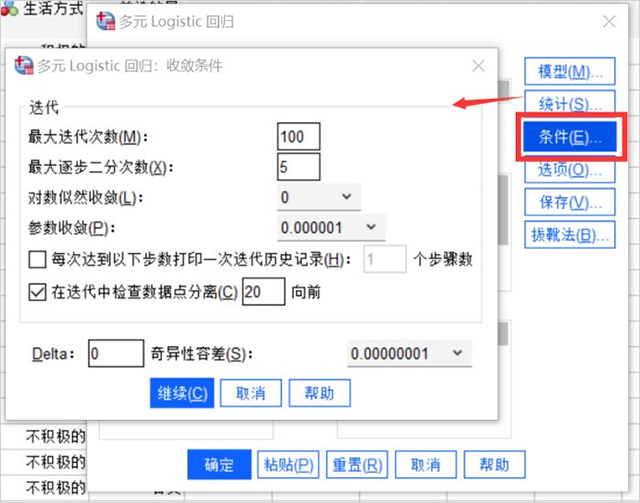
5、收敛条件
- 最大迭代数是数据进行回归分析时可进行迭代的次数,这个数值必须是大于或小于100的整数,最大步骤对分设置的是迭代时的等分数,系统默认是5。
- 对数似然收敛可设置收敛值,回归过程中对数似然比函数是大于设定值的;参数收敛的数值设置类似。
- 本例中该对话框保持默认即可。
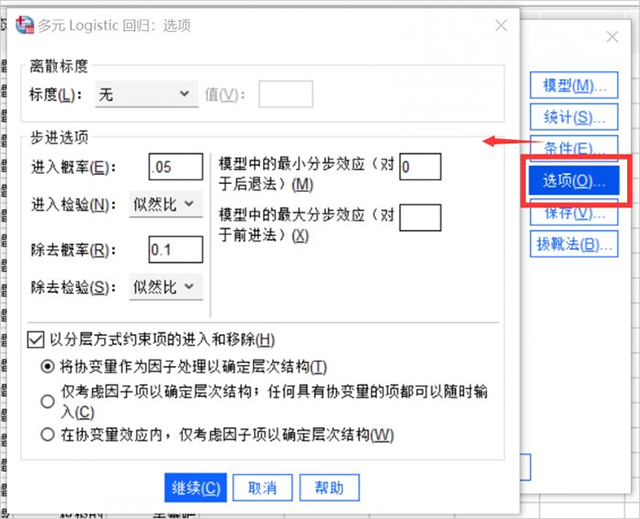
6、选项设置
- 在选项对话框中设置离散度量为“无”。
- 数据的进入概率为0.05,出去概率为0.1,这两个参数中,前者越大,进入模型的数据越多;后者越小,数据被剔除的越多,进入和出去方法均选择似然性。
- 其余保持默认即可。
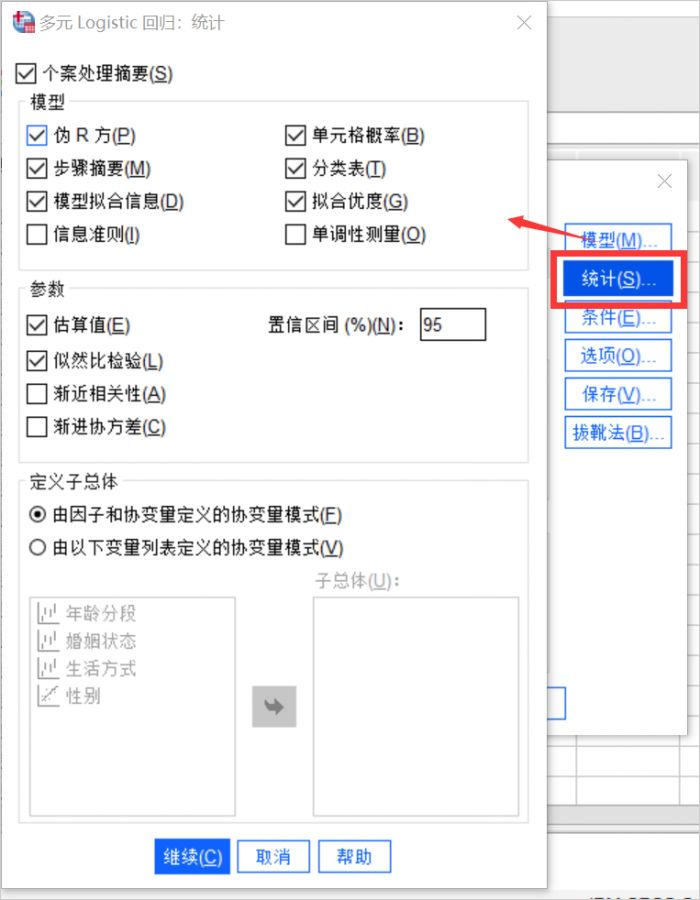
7、保存设置
在这个对话框中设置需要保存的变量,如果需要将模型信息输出到XML文件,也可以在次设置。
8、完成分析
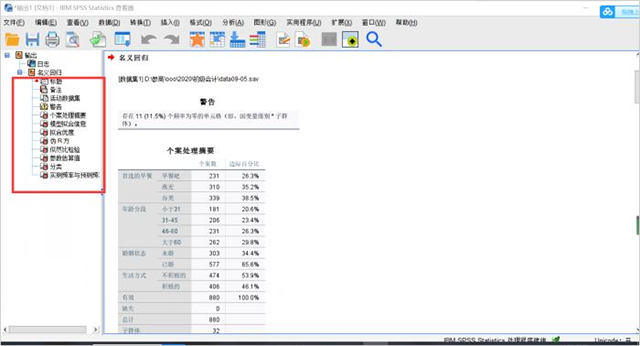
完成上述设置后,就可以在日志输出窗口中查看分析结果啦!分析结果包含多个表格,每个数值都有特定含义,大家在分析的时候也要认真观察数据哦!
spss入门学习使用技巧
一、多项选择题数据的输入
方法1:多重二分法。有多少选项就设多少个变量,某个个案选择了某项则在该变量名下录入“1”,未选择某项则录入“0”,即将每个变量变成类似于“是”、“否”的选择题。
方法2:多重分类法。有多少选项就设多少个变量,某个个案选择了某项则在该变量名下录入“1”,未选择某项则录入“0”。例如,某个个案选择了第“1”、“3”、“4”项, 则依次录入“1、 0、 1、 1、 0、 0”。
方法3:多重分类法。选了多少项就设置多少个变量,如命名为 seq1、seq2 和 seq3 ,如果某个个案选择了第“1”、“3”、“2”项时,则依次输入“1”、“3”、“2”。
方法4:多重分类法,利用Excle的分列功能。
- 设置一个变量,命名为 var1。
- 录入数据。例如 ,某个个案选择了第“1、 3、 2”项,则输入“1 3 2”。
- 将该多选题及其数据另存为 Excle文件。
- 在excle 中将 var1 这一个变量分列 ,步骤是“选定该变量 →数据 →分列 →固定宽度 →下一步→使用鼠标分列 →下一步 →完成。这样 ,原来的一个变量组成的数据库转化为由几个变量组成的新的数据库 。
- 将新的变量 Seq1 ,Seq2 ,Seq3 保存。
- 最后 ,使用 SPSS软件读取该数据文件
二、分析方法
SPSS提供了三种相关分析方法:
1、Bivariate 方法
- 用于进行两个/多个变量间的参数/非参数相关分析。如果是多个变量,则给出两两相关的分析结果。该方法十分常用 通常会占到所有相关分析的 95%以上。
2、Partial方法
- 用于偏相关分析,通常在进行相关分析的两个变量其取值均受到其他变量的影响时使用。
3、Distances 方法
- 对同一变量内部各观察单位间的数值或各个不同变量间进行距离相关分析,在教育教学研究中使用较少。
- 语文成绩与数学成绩是不是相关?假设采集30 名学生的数学和语文成绩进行分析。
- 输入数据后,对数据的信度进行检查,并绘制散点图,直观查看两变量间是否有相关性。然后即进行相关分析:
- 在菜单中选择 Analyze-->Correlate-->Bivariate (即:分析-->相互关系-->二变量),将需要进行分析的变量:数学和语文加入Variables 列表中。
- 在界面中确认选中“ Pearson ”即要求计算皮尔森相关系数,确认选中 Two-tailed ,即要求进行两边检测,选中 Flag significantcorrelations 即当变量间有关时,显示相关标记,设置完成后 ,单击OK SPSS 即会帮我们算出结果。
其它版本下载
-
查看详情
ibm spss statistics 26 mac中文版
 1.89G
1.89G
-
查看详情
ibm spss statistics 25 mac版 720.73M
-
查看详情
spss27mac版 v27.0.1727.1M
-
查看详情
ibm spss statistics 28.0mac版
 932.49M
932.49M
发表评论
9人参与,9条评论- 第9楼山东省泰安市联通网友发表于: 2020-05-18 11:21:11
- 好用方便0盖楼(回复)
- 第8楼山西省晋城市联通网友发表于: 2020-04-21 15:07:00
- 很好的0盖楼(回复)
- 第7楼新疆巴音郭楞州移动网友发表于: 2020-04-19 12:10:39
- 很满意0盖楼(回复)
- 第6楼吉林省白城市联通网友发表于: 2019-12-21 19:32:00
- 很好用0盖楼(回复)
- 第5楼安徽省合肥市巢湖市电信网友发表于: 2019-10-21 23:08:47
- 好好好0盖楼(回复)
- 第4楼台湾省中华电信网友发表于: 2019-10-06 12:20:04
- 感謝提供0盖楼(回复)
- 第3楼台湾省中华电信(HiNet)数据中心网友发表于: 2019-05-29 00:40:38
- 謝謝分享0盖楼(回复)
- 第2楼陕西省咸阳市电信网友发表于: 2019-04-18 18:23:23
- 非常好用的软件0盖楼(回复)
- 第1楼运营商级NATIP地址网友发表于: 2019-03-28 15:45:26
- 很好用的呀0盖楼(回复)
软件排行榜
热门推荐
 钉钉mac电脑版 v7.6.55官方版434.24M / 简体中文
钉钉mac电脑版 v7.6.55官方版434.24M / 简体中文 印象笔记mac版 v9.7.29官方版186.11M / 简体中文
印象笔记mac版 v9.7.29官方版186.11M / 简体中文 云之家mac版 v4.5.2官方版175.76M / 简体中文
云之家mac版 v4.5.2官方版175.76M / 简体中文 飞书会议室mac版 v7.38.3官方版262.36M / 简体中文
飞书会议室mac版 v7.38.3官方版262.36M / 简体中文 如流mac版 v2.3.49.4348.83M / 简体中文
如流mac版 v2.3.49.4348.83M / 简体中文 亿图脑图mac版(个人版) v12.2.4官方版397.72M / 简体中文
亿图脑图mac版(个人版) v12.2.4官方版397.72M / 简体中文 Keybase for mac(团队协作工具) v6.5.0196.41M / 英文
Keybase for mac(团队协作工具) v6.5.0196.41M / 英文 drawio mac版 v26.0.15官方版133.89M / 简体中文
drawio mac版 v26.0.15官方版133.89M / 简体中文 mindline思维导图mac版 v4.5.369.27M / 简体中文
mindline思维导图mac版 v4.5.369.27M / 简体中文 typora mac中文版 v1.9.413.88M / 简体中文
typora mac中文版 v1.9.413.88M / 简体中文
 赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理
赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理