

spark高级数据分析是一本Spark实用手册,由著名大数据公司Cloudera的四名数据科学家编写,他们联袂展示了利用Spark进行大规模数据分析的若干模式,而且每个模式都自成一体。全书将Spark、统计学方法和真实数据集结合起来,通过实例向读者讲述了怎样解决分析型问题。spark高级数据分析首先介绍了Spark及其生态系统,接着详细介绍了将分类、协同过滤及异常检查等常用技术应用于基因学、安全和金融领域的若干模式。如果你对机器学习和统计学有基本的了解,并且会用Java、Python或Scala编程,这些模式将非常有助于你开发自己的数据应用。
内容介绍
《Spark高级数据分析》是使用Spark进行大规模数据分析的实战宝典,由大数据公司Cloudera的数据科学家撰写。四位作者首先结合数据科学和大数据分析的广阔背景讲解了Spark,然后介绍了用Spark和Scala进行数据处理的基础知识,接着讨论了如何将Spark用于机器学习,同时介绍了常见应用中几个常用的算法。此外还收集了一些更加新颖的应用,比如通过文本隐含语义关系来查询Wikipedia或分析基因数据。
作者简介
Sandy Ryza是Cloudera公司数据科学家,Apache Spark项目的活跃代码贡献者。领导了Cloudera公司的Spark开发工作。他还是Hadoop项目管理委员会委员。
Uri Laserson是Cloudera公司数据科学家,专注于Hadoop生态系统中的Python部分。
Sean Owen是Cloudera公司EMEA地区的数据科学总监,也是Apache Spark项目的代码提交者。他创立了基于Spark、Spark Streaming和Kafka的Hadoop实时大规模学习项目Oryx(之前称为Myrrix)。
Josh Wills是Cloudera公司的高级数据科学总监,Apache Crunch项目的发起者和副总裁。
spark高级数据分析章节目录
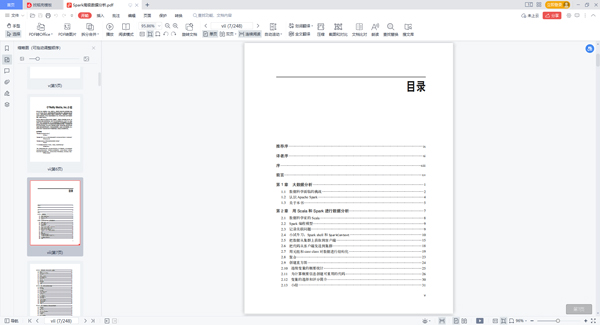
推荐序 ix 译者序 xi 序 xiii 前言 xv 第1 章 大数据分析 1 1.1 数据科学面临的挑战 2 1.2 认识Apache Spark 4 1.3 关于本书 5 第2 章 用Scala 和Spark 进行数据分析 7 2.1 数据科学家的Scala 8 2.2 Spark 编程模型 9 2.3 记录关联问题 9 2.4 小试牛刀:Spark shell 和SparkContext 10 2.5 把数据从集群上获取到客户端 15 2.6 把代码从客户端发送到集群 18 2.7 用元组和case class 对数据进行结构化 19 2.8 聚合 23 2.9 创建直方图 24 2.10 连续变量的概要统计 25 2.11 为计算概要信息创建可重用的代码 26 2.12 变量的选择和评分简介 30 2.13 小结 31 第3 章 音乐推荐和Audioscrobbler 数据集 33 3.1 数据集 34 3.2 交替最小二乘推荐算法 35 3.3 准备数据 37 3.4 构建第一个模型 39 3.5 逐个检查推荐结果 42 3.6 评价推荐质量 43 3.7 计算AUC 44 3.8 选择超参数 46 3.9 产生推荐 48 3.10 小结 49 第4 章 用决策树算法预测森林植被 51 4.1 回归简介 52 4.2 向量和特征 52 4.3 样本训练 53 4.4 决策树和决策森林 54 4.5 Covtype 数据集 56 4.6 准备数据 57 4.7 第一棵决策树 58 4.8 决策树的超参数 62 4.9 决策树调优 63 4.10 重谈类别型特征 65 4.11 随机决策森林 67 4.12 进行预测 69 4.13 小结 69 第5 章 基于K 均值聚类的网络流量异常检测 71 5.1 异常检测 72 5.2 K 均值聚类 72 5.3 网络入侵 73 5.4 KDD Cup 1999 数据集 73 5.5 初步尝试聚类 74 5.6 K 的选择 76 5.7 基于R 的可视化 79 5.8 特征的规范化 81 5.9 类别型变量 83 5.10 利用标号的熵信息 84 5.11 聚类实战 85 5.12 小结 86 第6 章 基于潜在语义分析算法分析维基百科 89 6.1 词项- 文档矩阵 90 6.2 获取数据 91 6.3 分析和准备数据 92 6.4 词形归并 93 6.5 计算TF-IDF 94 6.6 奇异值分解 97 6.7 找出重要的概念 98 6.8 基于低维近似的查询和评分 101 6.9 词项- 词项相关度 102 6.10 文档- 文档相关度 103 6.11 词项- 文档相关度 105 6.12 多词项查询 106 6.13 小结 107 第7 章 用GraphX 分析伴生网络 109 7.1 对MEDLINE 文献引用索引的网络分析 110 7.2 获取数据 111 7.3 用Scala XML 工具解析XML 文档 113 7.4 分析MeSH 主要主题及其伴生关系 114 7.5 用GraphX 来建立一个伴生网络 116 7.6 理解网络结构 119 7.6.1 连通组件 119 7.6.2 度的分布 122 7.7 过滤噪声边 124 7.7.1 处理EdgeTriplet 125 7.7.2 分析去掉噪声边的子图 126 7.8 小世界网络 127 7.8.1 系和聚类系数 128 7.8.2 用Pregel 计算平均路径长度 129 7.9 小结 133 第8 章 纽约出租车轨迹的空间和时间数据分析 135 8.1 数据的获取 136 8.2 基于Spark 的时间和空间数据分析 136 8.3 基于JodaTime 和NScalaTime 的时间数据处理 137 8.4 基于Esri Geometry API 和Spray 的地理空间数据处理 138 8.4.1 认识Esri Geometry API 139 8.4.2 GeoJSON 简介 140 8.5 纽约市出租车客运数据的预处理 142 8.5.1 大规模数据中的非法记录处理 143 8.5.2 地理空间分析 147 8.6 基于Spark 的会话分析 149 8.7 小结 153 第9 章 基于蒙特卡罗模拟的金融风险评估 155 9.1 术语 156 9.2 VaR 计算方法 157 9.2.1 方差- 协方差法 157 9.2.2 历史模拟法 157 9.2.3 蒙特卡罗模拟法 157 9.3 我们的模型 158 9.4 获取数据 158 9.5 数据预处理 159 9.6 确定市场因素的权重 162 9.7 采样 164 9.8 运行试验 167 9.9 回报分布的可视化 170 9.10 结果的评估 171 9.11 小结 173 第10 章 基因数据分析和BDG 项目 175 10.1 分离存储与模型 176 10.2 用ADAM CLI 导入基因学数据 178 10.3 从ENCODE 数据预测转录因子结合位点 185 10.4 查询1000 Genomes 项目中的基因型 191 10.5 小结 193 第11 章 基于PySpark 和Thunder 的神经图像数据分析 195 11.1 PySpark 简介 196 11.2 Thunder 工具包概况和安装 199 11.3 用Thunder 加载数据 200 11.4 用Thunder 对神经元进行分类 207 11.5 小结 211 附录A Spark 进阶 213 附录B 即将发布的MLlib Pipelines API 221 作者介绍 226 封面介绍 226
使用说明
1、下载并解压,得出pdf文件
2、如果打不开本文件,请务必下载pdf阅读器
3、安装后,在打开解压得出的pdf文件
4、双击进行阅读
发表评论
0条评论软件排行榜
热门推荐
 南方Plus电脑版 v12.3.023.89M / 简体中文
南方Plus电脑版 v12.3.023.89M / 简体中文 网易新闻电脑版 v113.697.68M / 简体中文
网易新闻电脑版 v113.697.68M / 简体中文 潇湘书院电脑版 v2.3.13.91049.58M / 简体中文
潇湘书院电脑版 v2.3.13.91049.58M / 简体中文 开源阅读电脑版 v3.25.03010017.8M / 简体中文
开源阅读电脑版 v3.25.03010017.8M / 简体中文 cnki全球学术快报电脑版 v1.0.4104.49M / 简体中文
cnki全球学术快报电脑版 v1.0.4104.49M / 简体中文 网易云阅读电脑版 v6.7.226.41M / 简体中文
网易云阅读电脑版 v6.7.226.41M / 简体中文 京东读书电脑版 v1.13.4官方版2.13M / 简体中文
京东读书电脑版 v1.13.4官方版2.13M / 简体中文 吉利博瑞用户手册 pdf高清版57.89M / 简体中文
吉利博瑞用户手册 pdf高清版57.89M / 简体中文 未公开的Oracle数据库秘密 迪贝斯pdf扫描版34.69M / 简体中文
未公开的Oracle数据库秘密 迪贝斯pdf扫描版34.69M / 简体中文 PHP语言精粹电子书 pdf扫描版25.72M / 简体中文
PHP语言精粹电子书 pdf扫描版25.72M / 简体中文
 赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理
赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理